
科技公司的模型在探索與利用之間的權衡
Shin-Min Hsu | Data Scientist | Author of 科技巨頭的演算法大揭秘
活動主辦單位:Taiwan Data Science Meetup 台灣資料科學社群
講者介紹
Shin-Min Hsu 台大學碩畢業,目前在資安公司擔任 Data Scientist,參與了2022 iThome 鐵人賽,隨後出版了【科技巨頭演算法大揭密】,本次主題會聚焦在科技巨頭 — Spotify 以及 Netflix 的推薦系統演算法,特別在於探索和利用之間的權衡。
Press enter or click to view image in full size

講者 PPT— 講者介紹
Press enter or click to view image in full size

講者 PPT — 講者書籍
摘要
本文將分成以下部分進行探討
- Spotify & Netflix 個人化首頁
- 探索與利用的權衡
- Spotify 的首頁歌曲推薦模型 BART
- Netflix — 「繼續觀賞」內容列
- 為推薦內容提供解釋
Spotify & Netflix 個人化首頁
Spotify 與 Netflix 的個人化首頁有一些共同的特徵如下
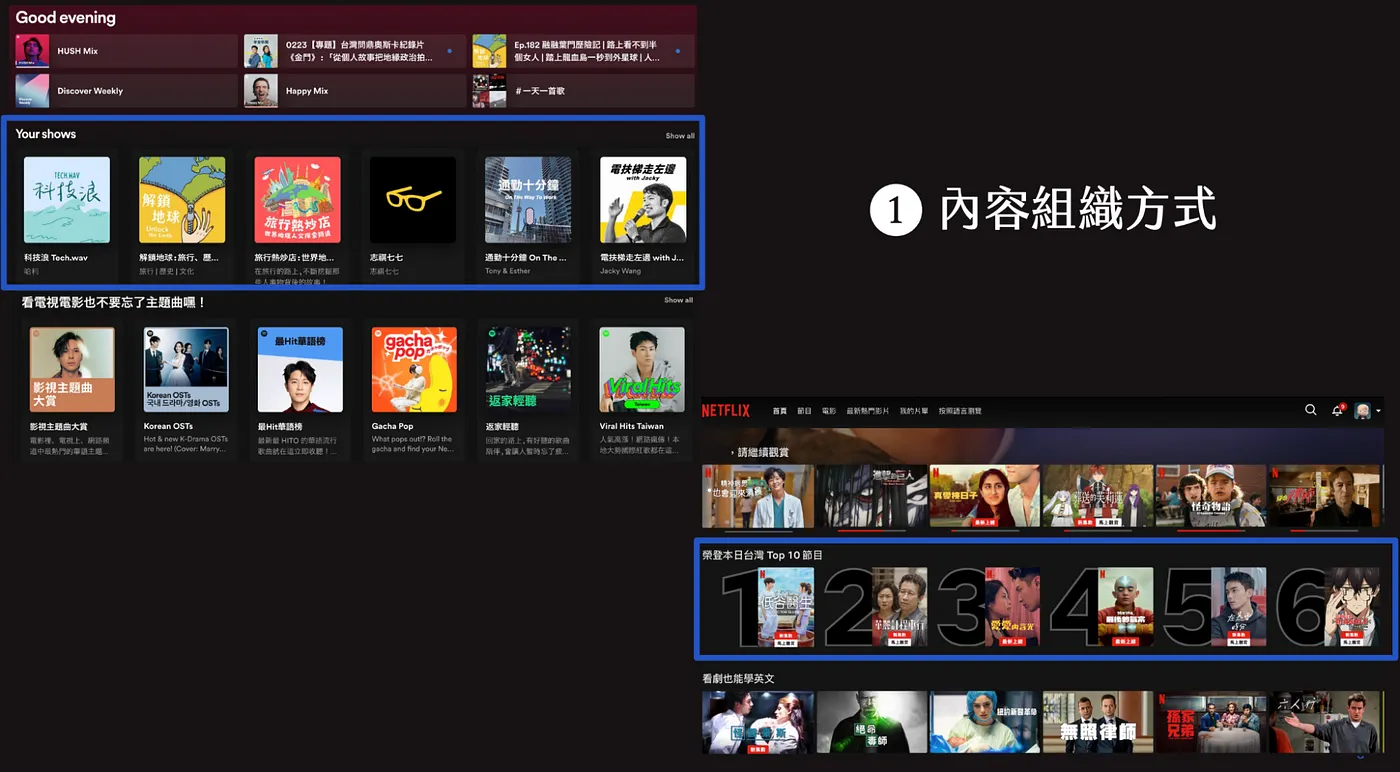
內容組織的方式相似 — 橫排是一個種類,裡面是內容,能夠左右滑動或者點進進入類別。
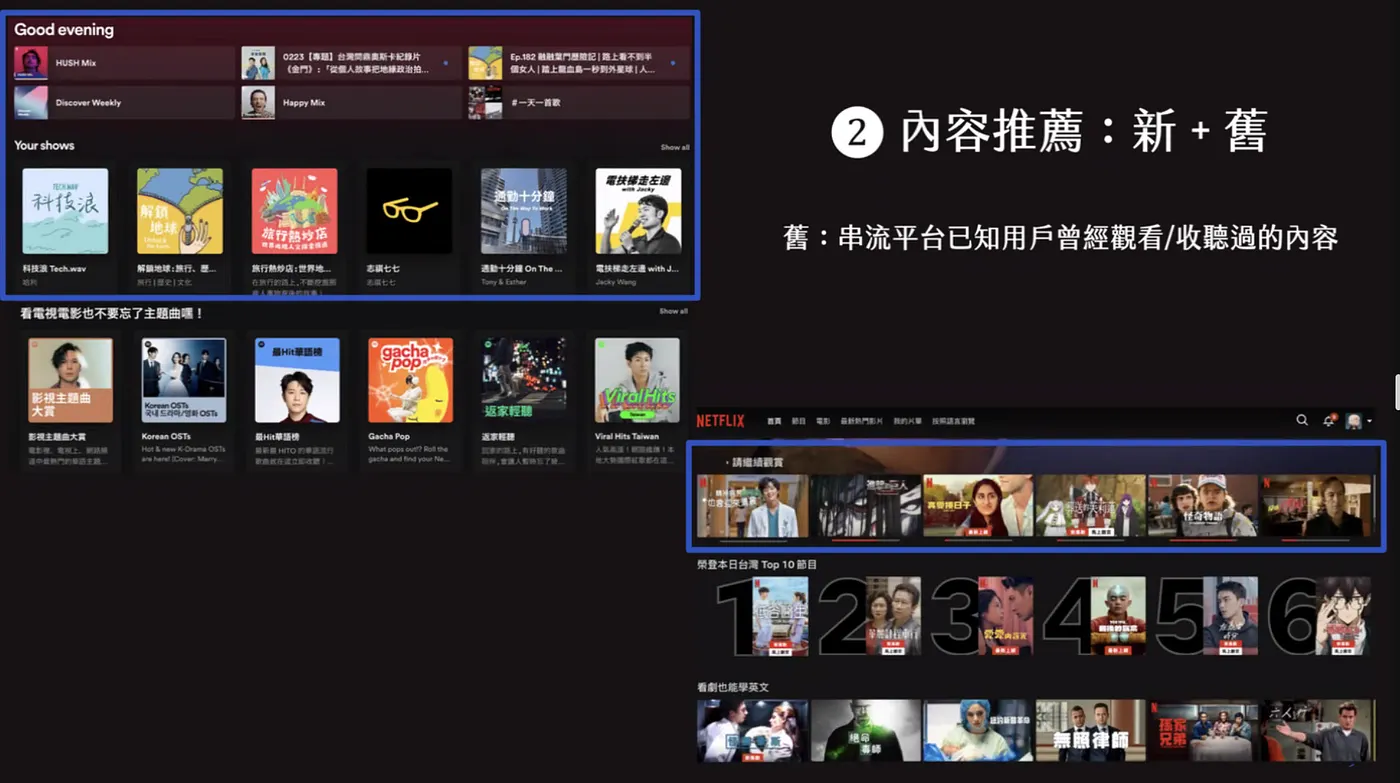
內容推薦都以 新 + 舊 的方式組合,舊的內容通常是互動過的內容,例如
- Spotify 會放上已經有聽過的 Podcast 頻道的不同 episode
- Netflix 會放上繼續觀看,也就是已經看過的影集,但還沒看完的
- 新的內容則是使用者沒有看過,但是根據過往的喜好、興趣做出不同的預測,推送給使用者
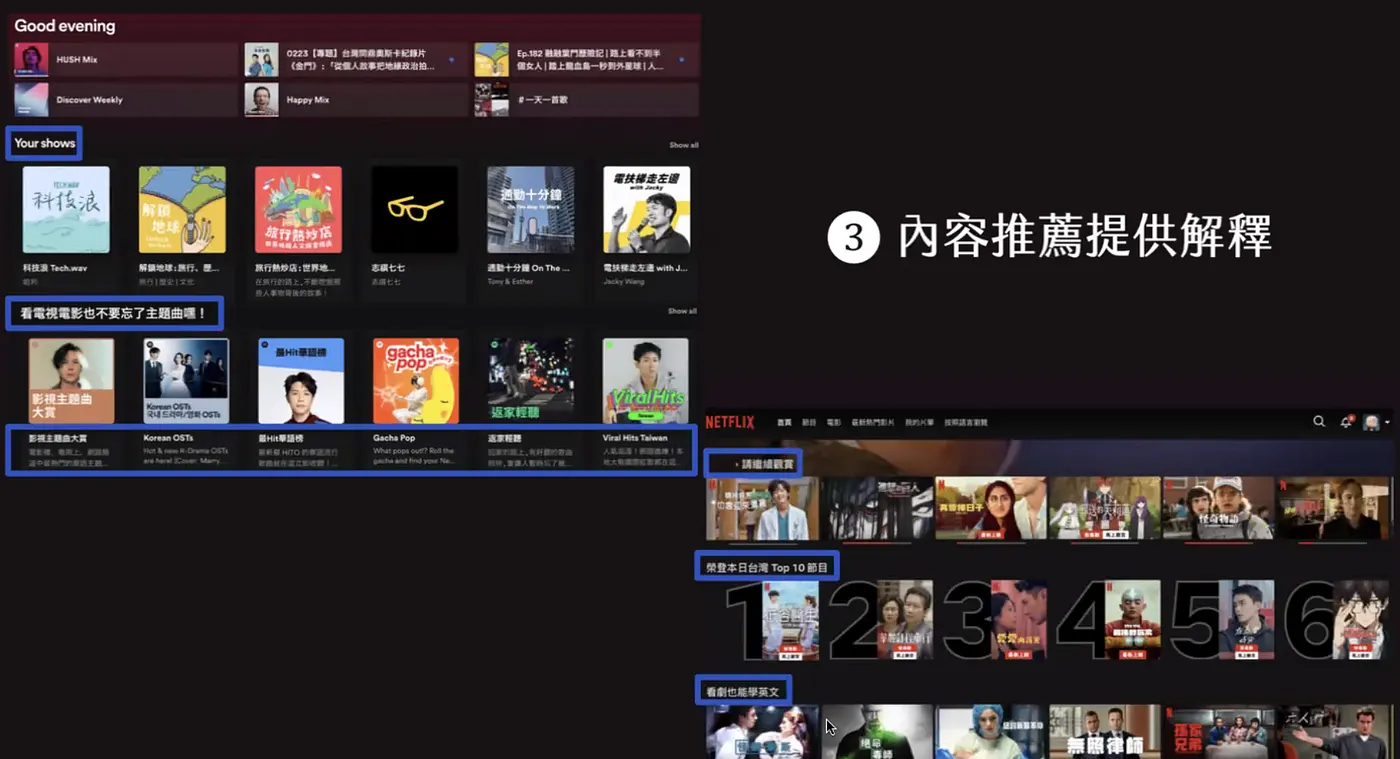
內容提供都有提供解釋,例如
- 因為我曾觀賞過、看劇也能學英文等
Press enter or click to view image in full size

講者 PPT— 內容組織方式比較
Press enter or click to view image in full size
講者 PPT — 內容新鮮度比較
Press enter or click to view image in full size
講者 PPT — 內容推薦解釋
本文會先從新與舊開始聊聊探索與利用的權衡,並且說明為什麼會提供不同的推薦解釋。
探索與利用的權衡
Spotify 的首頁歌曲推薦模型 BART
Press enter or click to view image in full size
講者 PPT — BART in Spotify
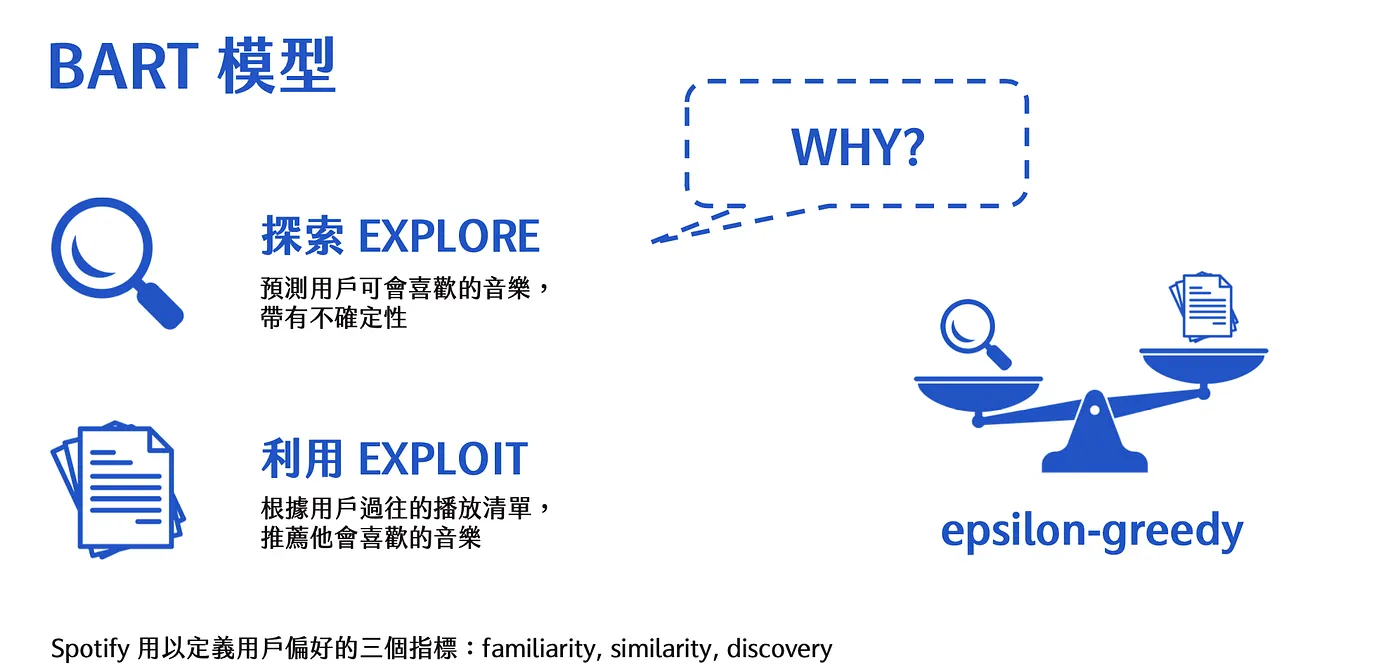
Bandits 是 1 個常見的演算法,rescplanations 則是一個自創詞,recommendation 跟 explanations 的合併在一起的詞,以下介紹 Bandits 這個演算法
Bandits — 拉霸機
- 大家在玩拉霸機或是吃角子老虎機的時候,可以拉不同的手臂,並得到不同的獎勵,選擇要拉哪一個手臂時,可能會根據過去的經驗來決定,例如說拉這個比較容易得到獎勵,或者拉這隻臂都沒有得到獎勵,所以不拉它,因此每一次拉臂之前,可以參考過去的經驗,或者拉一個全新的臂。
- 拉霸機可以類比到推薦系統,Spotify 借用這個概念,來平衡所謂的探索和利用
- 探索 — 不會仰賴先前過去的經驗,隨機做出新的選擇
- 利用 — 根據過去經驗,每次按拉 C 這個臂,獲取的 reward 會最高,所以一直拉 C臂 — 參考我之前過去的經驗,然後選擇經驗最好的。
多臂餃子老虎機 — 預測,用戶可能會喜歡的音樂,例如最上面兩列,是筆者有聽過的音樂 / 節目,最下面則是,我沒有聽過我的歌單,但他預測我可能會喜歡。
Press enter or click to view image in full size

講者 PPT — Multi-armed bandit
評估算法好壞的方式則是需要設計不同的指標來衡量推薦清單的表現, Spotify 設計的衡量指標如下:
familarity — 對於特定使用者,歌單內的歌曲播放越多次,對於該歌曲越熟悉, familarity 能夠被計算在歌曲、歌單、藝術家、podcast 單集等物品上
- 其中主動點擊歌曲以及被動播放在分析上會被區分開來,表示不同的使用者行為。
discovery — 如果特定使用者,半年內都沒有播放過這首歌,而最近有主動 / 被動點擊,就可判定為 discovery ,同樣夠被計算在歌曲、歌單、藝術家、podcast 單集等物品上
similarity — 該指標比較直觀,就是對於特定的歌曲,與使用者過往聽過歌曲的相似度為何
Press enter or click to view image in full size

講者 PPT— metrics to define user preference
Spotify 就是利用這三個指標來去衡量算出來的歌單,那麼,要如何平衡所謂的探索跟利用呢?
他們使用的是 Epsilon Greedy ,這裡不會展開太多數學或是深入的理論,high level 的概念來看,其實就是設定 Epsilon 的機率值,例如 0.3,那麼每次就有 0.3 的機會利用, 0.7 的機率探索用,所以每次進入首頁時, Spotify 就跑做一次探索/利用。
到此,大家可能會想說,那為什麼我們不能就直接都用利用就好了,利用的原因 — 因為可以百分之百確定,用戶一定會喜歡的嘛。因為他都已經曾經播過了,而且他可能 familiarity 很高,因為使用者很熟悉,為什麼還要冒著風險,作「探索」呢?
- 因為 Spotify 它在建模型的時候,有做一些使用者的研究,然後他們有發現,使用者在使用 Spotify 的時候,除了一直聽自己曾經喜歡過的音樂,也會希望,或是預期 Spotify 可以推薦一些,他們從來沒有聽過,但他們可能會喜歡的音樂。 這和講者本人聽到身邊朋友使用 Spotify 的原因也蠻接近的,所以有提供探索這個功能的話,那的確是會提高使用者對 Spotify 的偏好。
- Spotify 的分析也指出,如果使用者被推薦了一首新的歌,然後他如果不喜歡的話,其實對 Spotify 不是負面的評價,只是個中性的訊號,概念上就是使用者不喜歡,並且跳過歌曲,對 Spotify 來說,反而是個正面的事情,因為它就是可以更知道用戶喜歡什麼樣的歌,然後可以再更打造用戶會喜歡的模型。
Press enter or click to view image in full size
講者 PPT — reward function
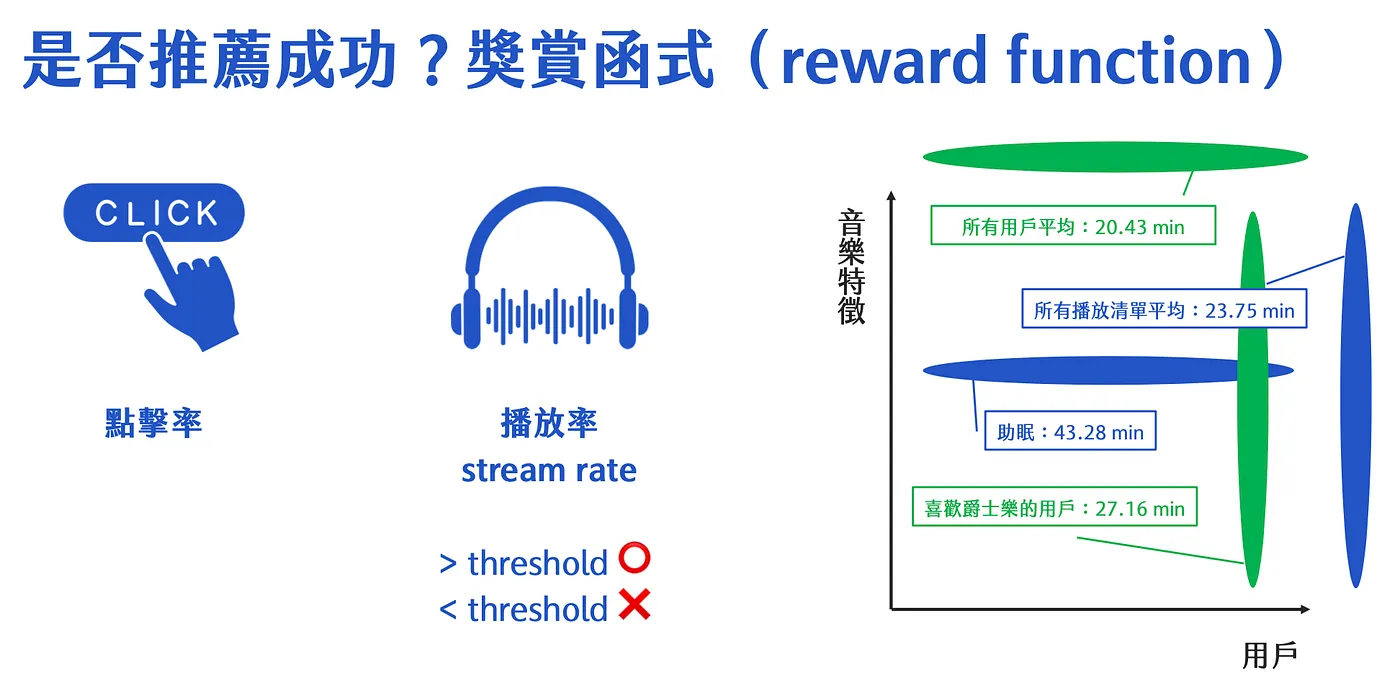
要怎麼定義用戶是不是會推薦成功呢?一般我們比較常聽到的應該就是點擊率,但看點擊率的話,其實對音樂這種串流平臺來講,不太適合,
因此 Spotify 使用的是播放率,點進一首歌,聽超過某個 threshold 之後,就定義為推薦成功,反之則使推薦失敗。
而播放率 threshold 的定義,會隨著不同的音樂特徵而有所不同,分析如上圖
- 不管類別,考慮所有使用者的播放清單平均值 — 23.75 mins。
- 助眠清單 — 43.28 mins。
- 喜歡爵士樂的使用者 — 27.16 mins。
也因此,播放率的 threshold 會根據以上分析有不同的標準,而 Spotify 推出 BART 模型後,推薦指標上升的數字相當有成長
Press enter or click to view image in full size
Netflix — 「繼續觀賞」內容列
Press enter or click to view image in full size

講者 PPT — Netflix CW Content Raw
Netflix 的繼續觀賞內容列,講者覺得有趣的地方是
- 按照字面意思,內容影片可能只是曾經看過的影片,並且按觀看時間排序,後來發現並不是如此。
- 「繼續觀賞」 有時處在首頁上面,有時處在首頁下面。
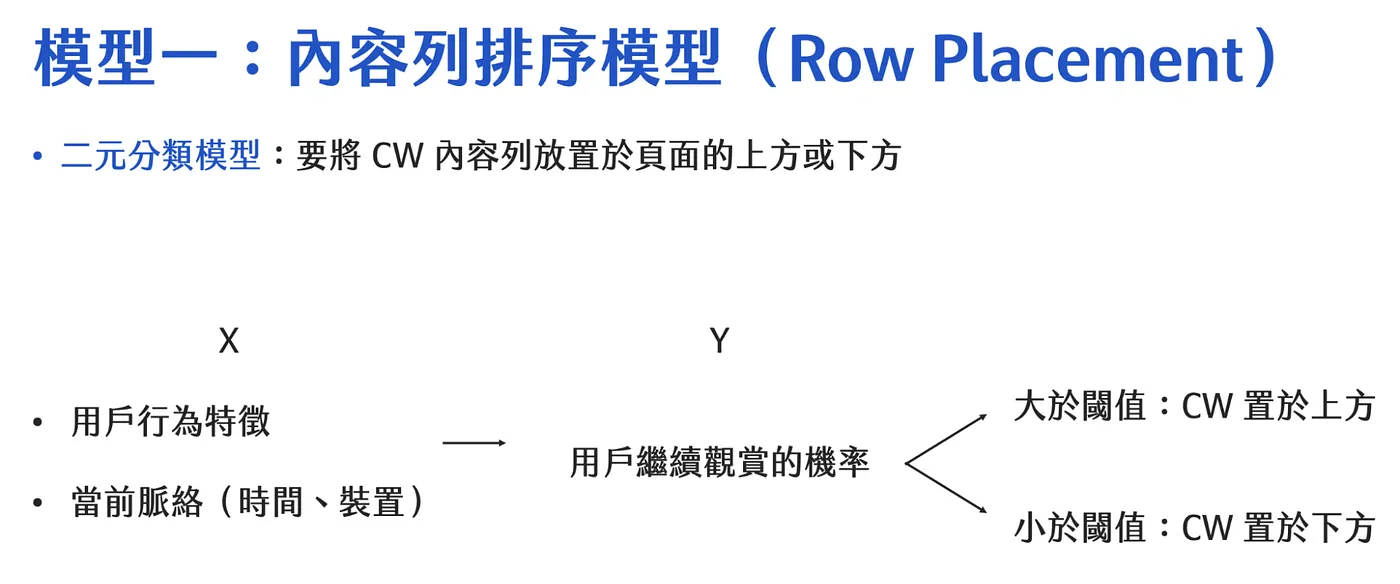
因此特別閱讀了 Netflix 的相關文獻,根據資料分析結果, Netflix 將使用者切成兩種行為模式,探索模式以及繼續觀看模式 (追劇模式)
當使用者處於繼續觀看模式時,須將「繼續觀賞」放到垂直排列的前面,讓使用者可以快速找到
反之則是探索模式,「繼續觀賞」可以被排在首頁下方
Press enter or click to view image in full size

講者 PPT — Netflix CW Goal 1
Press enter or click to view image in full size

講者 PPT — Netflix CW Model 1
Press enter or click to view image in full size
講者 PPT — Netflix CW Goal 2
「繼續觀賞」的內容排列也會和 Context 有關係,最明顯的則是時間與裝置,例如在通勤時間,可能傾向看時間長度短的劇,並且使用手機,而晚上回到家用電視,則會選擇看不同的影集,這也可以被做成一個排序模型,來計算已經看過的影集,根據目前的使用者行為,哪個影集是最有可能被觀看的。
成效上, Netflix 發現如此操作之後, Precision @ Top1 有提升,且使用者減少了搜尋功能的使用,意味著使用者不需要額外搜尋自己要看的影片,就可以在首頁上找到
Press enter or click to view image in full size

講者 PPT — Netflix CW Model 2
為推薦內容提供解釋
Press enter or click to view image in full size

講者 PPT — 推薦清單 & 推薦解釋
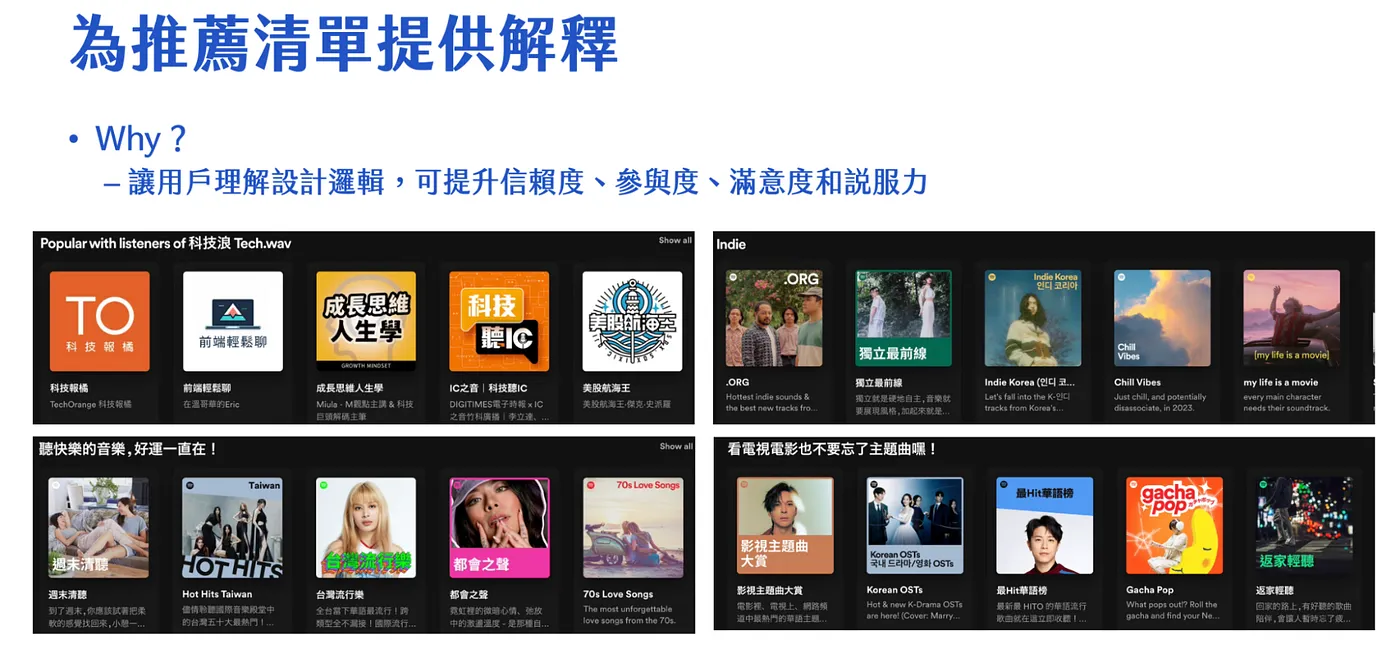
Spotify 從使用者的研究發現,為推薦清單提供解釋的話,可以讓理解他們為什麼要設計這樣的列進而提升用戶對這個推薦系統的信賴度、參與度、滿意度跟說服力,進而促進點擊
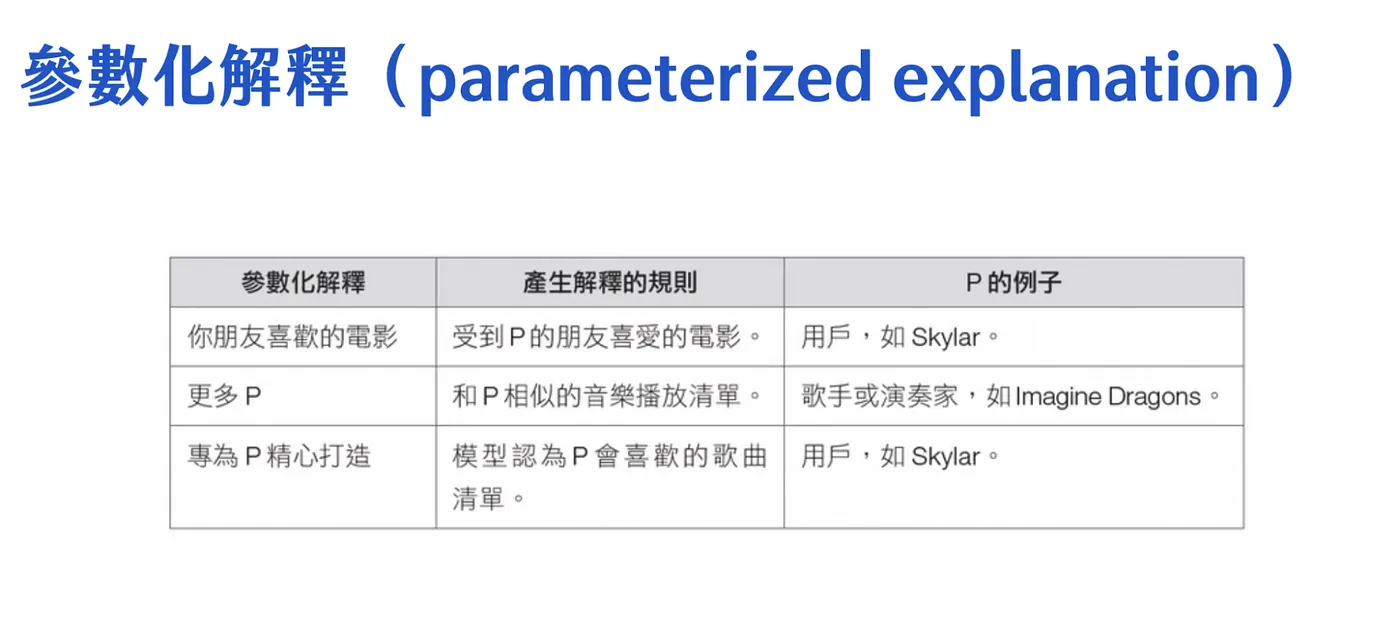
操作方式是參數化解釋,概念上就是寫一段解釋,然後中間挖空格,就像模板一樣,在套入不同 user / artist 的名字
Press enter or click to view image in full size
講者 PPT— 參數化解釋
並且在研究報告中發現,播放清單的解釋跟流量是有關的,有兩種推測的原因
- 有可能是歌單本身就很棒,哪一種解釋是沒有差異的
- 使用者被解釋所影響,進而點選了歌曲
近一步分析後,發現不同的歌曲/歌單,放在不同的解釋中,流量確實有差異,不同解釋的情況下, stream rate 最多可以提升到 20% ,也有發現某些解釋並沒有辦法產生有意義的流量差異,有可能是解釋描述較為模糊。
Press enter or click to view image in full size
講者 PPT — insights for explanation
Netflix 也做了相似的事情,來判斷不同解釋中的影片,有沒有不同的互動率,Netflix 還多做的一件事情是,給予不一樣的縮圖,是否有不同的互動率
不同縮圖的部分,如下圖所示,同樣一部「怪奇物語」,就有 4 種縮圖,會根據每個人的 profile,預測哪一個縮圖更可能促使使用者點擊,例如有的人喜歡看奧斯卡得獎的影片,同樣一部影集,就會給予有奧斯卡得獎的縮圖,或者有的人更傾向點擊風格陰暗,又或者縮圖演員表情中較為豐富的縮圖。
Press enter or click to view image in full size

講者 PPT— 證據選擇演算法
以上就是今天的演講內容,如果想看更多其他的內容,大家可以去看這本書,如果大家想了解更多關於科技巨頭的演算法細節,可以追蹤我的 IG — data.scientist.min。
Press enter or click to view image in full size

講者 PPT— 書籍內容
Press enter or click to view image in full size

講者 PPT — 作者聯絡資訊
筆記手:Yu Long
校稿:Ting Yu, Min
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!
https://www.facebook.com/groups/datasciencemeetup