
講者:Harry Lu|Data Analytics Manager @ Spotify
數據科學在舞弊防治的應用與挑戰(DS in Compliance and Fraud Detection)
數據科學在舞弊防治的應用與挑戰:
在這次分享中, Harry 將會與我們談論數據科學在 舞弊防治 的應用與挑戰。目前大部分的科技業都有不少資料科學的應用,從product/experiment/ml,但是在舞弊防治以及企業合規的部分,因為缺乏重視,所以往往在資料科學的運用跟不上企業本身的進步速度,導致有時會看到科技公司因為缺乏相關的數據與技術,而無法提升合規(Compliance)品質進而降低成本,Harry 稱之為 #科技公司中的不科技。隨著合規成本的快速提高,Harry 希望能夠分享其看法與經驗,讓上市公司的 compliance function 可以善用資料科學與機器學習,進而改善公司經營中非常脆弱的控制環節。
活動主辦單位: Taiwan Data Science Meetup 台灣資料科學社群
大綱:
一、講者介紹 (Introduction)
二、(Why) transferred from a fraud investigator to a data scientist
三、(How) to speak two languages: Connecting Data Science and Compliance
四、(What) to discover: DS Opportunities in Compliance
五、工商時間
六、Q&A
一、講者介紹 (Introduction)

Harry Lu
Harry 目前為 Spotify Data Analytics Manager,自2015年開始在亞太區從事舞弊調查的工作。後來2018年加入了 Johnson & Johnson 進行數據分析。去年加入 Spotify 帶領各項資料科學專案。Harry 的工作偏向協助 compliance function 並透過數據,找出可以運用的 insight。為了擴展技能,Harry 也同時參與公司的 Home Content Insight,在不同團隊間 rotate 增長見聞。

takeaways for three groups of people
Views are mine. I cannot disclose confidential info and will have to edit the story a bit when it comes to the confidential/compliance element.
(以下故事皆為真人真事改編)
這一次的演講 Harry 主要希望傳達公司內部的資料科學團隊/舞弊稽查部門/管理階層合作的可能,有助於舞弊稽查問題更有效率地解決。
二、(Why) transferred from a fraud investigator to a data scientist
- ask “what else” and “who else” to the data
資料科學是一個正在飛速發展領域,在不同的領域與產業上,有許多的資料科學家將其應用在個人化推薦、銷售極大化以及許許多多的應用商品上。像 Spotify 本身就是在以機器學習為核心的公司,著重在推薦系統上。

learned from fraud investigations in Biotech / Consulting
- 很難去問誰也在做這個課題
各大公司通常都不願意將這些資訊公布出來,因此,做舞弊調查的時候很難找到做類似事情的人詢問,假設在美國拿到一個案子,通常只 focus 在案件上,因此常常會產生一個疑問,如果有相同的案件發生,誰也可以去投入一些資源去解決這件事情(what else and who else)?
因此,進一步去思考,是不是可以建立模型幫助去預測可能的舞弊情況,幫助在舞弊調查中進行更加有效率。 - 現在的大公司都會有大量資料,但是常常會發現這些資料都不是針對舞弊調查的資料,無法用於舞弊調查上
近幾年來,有發現公司逐漸在收集這些資料,但以目前所知的進展,還是有一段路要走。 - 預防成本比補救成本低許多
透過機器學習幫助預防舞弊發生,可以省下高昂的花費,在美國一個案件通常會是20–30萬美金,相當於一個資料科學家的薪水,所以是可以快速看到效果的。
所以希望透過用資料科學的方法,幫助這件事情更有效率。如果可以妥善地運用公司的資料於舞弊防治上,那麼可以得到很好的效果。
綜合上述的經驗,讓 Harry 想要前往資料科學領域前進,著手改變科技中的不科技。
下圖為CFEs 預測未來公司組織將會面臨每年5% fraud 造成的利潤損失:

CFEs estimate lose 5% each year in fraud problems
其中的4. WFH 又更值得關注,疫情造成全球 WFH 變得稀鬆平常,也導致了舞弊更多的可能性,也讓無法用原先的方法去進行舞弊調查。
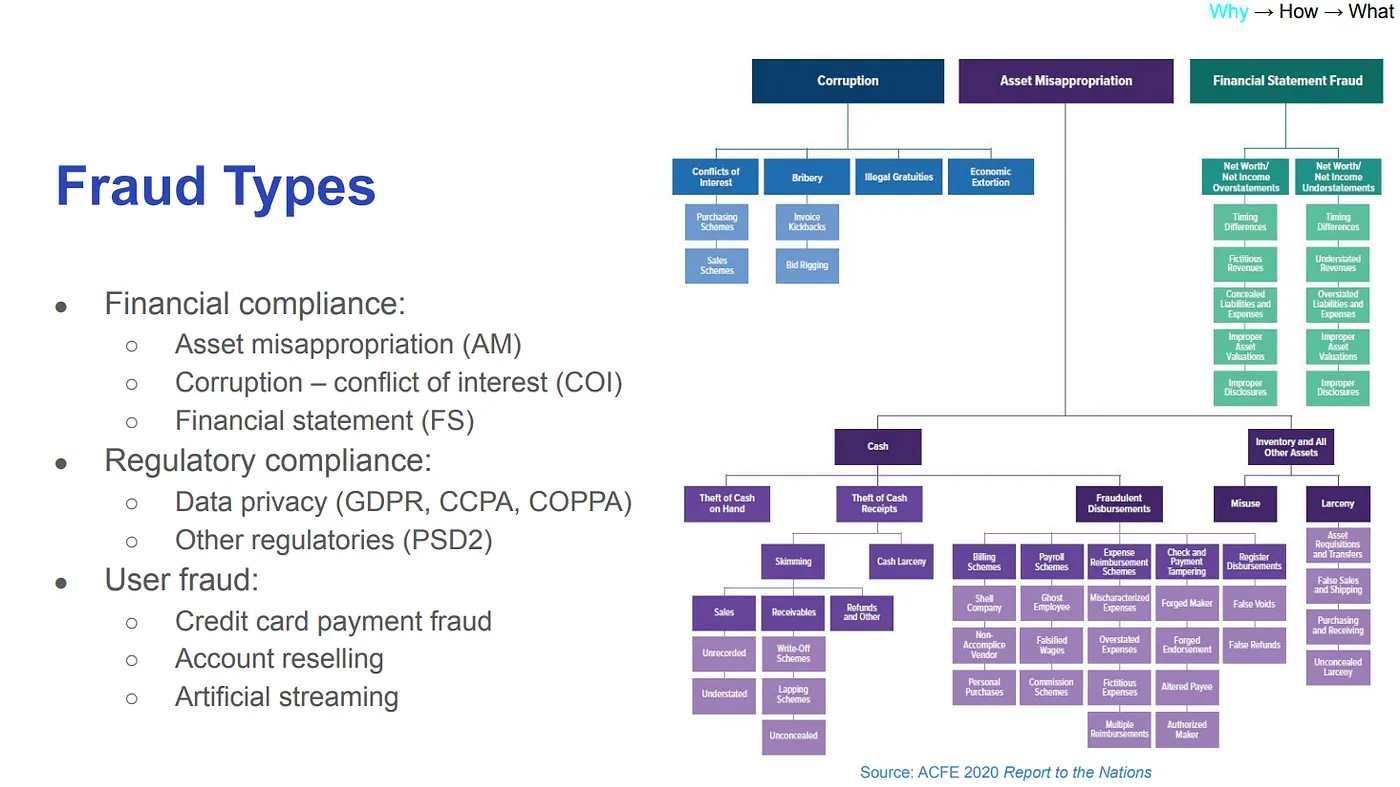
fraud types
上述為主要的舞弊類型,Harry 認為其中 AM、COI,是很適合公司嘗試用資料科學方法去解決的類型。
- AM(資產偷盜):盜用公司財產的行為,如 ghost vendor ,接收貨款之後,沒有提供相應的服務/商品。
- COI(利益衝突):如懷有私心地將親戚放置到不符合其能力之職位,造成公司的利益受損。能力不符合導致利益衝突,在公司文化非常常見,調查的時候很容易發現,但很難去預防,因為沒有相關數據去預防。
三、(How) to speak two languages: Connecting Data Science and Compliance
- connect data science resources with compliance business
故事1: 假設 Hrry 為Compliance 部門的一員,想要利用資料科學建造模型(model-based)去應用於Compliance environment,取代目前的rule-based analytics on financial controls。但他在Compliance 部門遭遇了下列問題:
- 沒有收集相關的資料
- 部門滿意於現行的人工方法
- 不確信是否能夠相信機器學習模型
- 教導律師、稽核人員去了解 coding、data science 比較沒有效率(成本太高)
— > 重重的阻礙,促使 Hrry 依然選擇舊有、人工的方法去處理問題。
故事2: 部門(Compliance / Data Science)間的溝通障礙

language by data science team

language by compliance team
資料科學團隊:我們可以透過 分群(clustering) 找尋相似性…
舞弊團隊:??
舞弊團隊:我們最近有一個 資產挪用問題(asset of misappropriation) 需要調查…
資料科學團隊:??
資料科學家與舞弊團隊雙方其實都非常願意合作,但是雙方不了解如何去溝通取得需要的資料、技術以及共識,其中有太多的技術 term,使得雙方難以合作。

如果有一個 中間人 ,可以去同時理解雙方所說的話,將其轉換到相同的基礎上,那麼就可以透過 資料科學 的方法去解決 舞弊 的問題。

藉由中間人,產生兩部門之間的 connection 之後,也許就可以去進行一個資料科學專案去解決企業內舞弊的問題。
例如:
- 透過模型去抓出 ghost vendor,節省過往花20-30萬美金的成本去解決問題,可能更有效率。
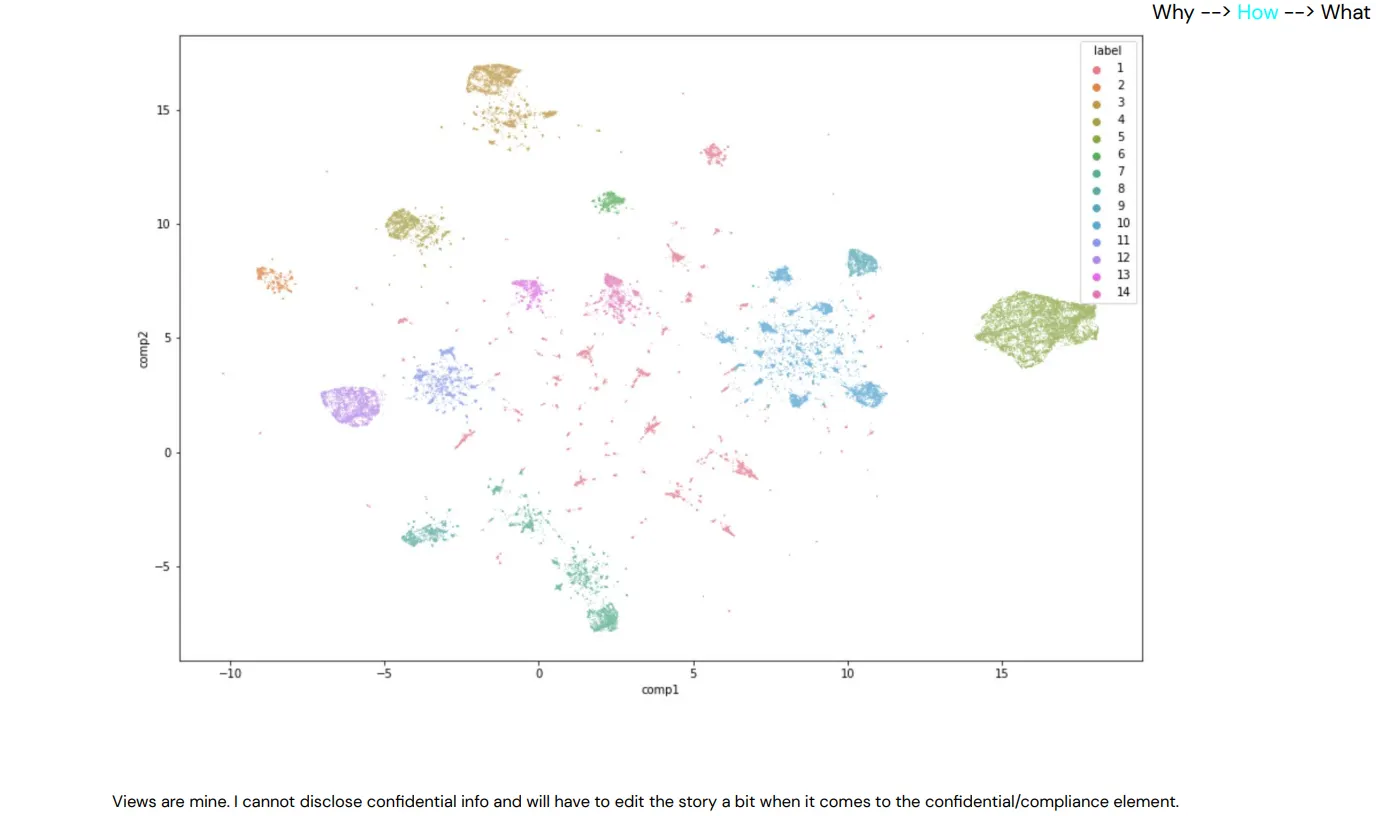
clustering
上圖為 Compliance 應用之一:clustering 的視覺化
- 如果想要做舞弊防治的專案,clustering 通常會是一個不錯的開頭,因為舞弊通常會有特定的 pattern,可以藉此去找出線索,進而解決問題。
四、(What) to discover: DS Opportunities in Compliance
- hidden opportunity in compliance and fraud investigations
如果是不太熟 Compliance 的人,有幾個方法或是關鍵字去幫助跨入這個領域。
以下用2個應用場景當作釋例
(story 1) How to find out ghost vendor(by employee)?
如果你是今天公司的資料科學家,可以用下列幾點去詢問,來開始 DS 專案
- Due Diligence by reviewing the vendor application
- Screening on the vendor owner
- Fuzzy match(90% confidence parameter) on between employee(發現一些特殊的pattern,將發現轉給調查人員,進而找到更深的證據)
- Transfer the address to latitude and longitude (using Geopy and Geopandas Libraries)
a. And calculate the minimum of distance between any vendor and employee(美國地非常大,常常可以自己設定地址,有時候可以透過此方法取得重大進展)
b. Neighbor ghost company/Home manufactory/Different address but same location
(story 2) How to find out under-age user
常常發生在 general public app,如 Spotify、Netflix, YouTube,Facebook,可能會有 under-age user 問題需要解決。
- Have a group of under age users (maybe from the kid app)
a. Data collection will be different, but find out the feature we collect for recommendation - Have a group of true adult users
a. Credit Card Verification (assume the bank do the age check) - Binary Prediction
- Roll with verification popup from the user end(跳出通知給潛在的under-age user有kid app可以使用)
還有一些其他類型的應用例子
- pattern discovery
希望找出資料中哪一些特徵對於目標是重要,是決定性的特徵。在舞弊稽查中非常重要。 - ML and then reverse engineering for simplified rulesets
a. Example: T&E fraud, payment fraud
很多時候,在 Compliance 問題中,我們並不會有live data。我們可能是透過跑了一次 clustering ,我們透過 clustering 的結果,透過 reverse engineering 去解析 clustering ,找出一個簡單的規則判斷,找出一個簡單版本去找到大部分的舞弊狀況。 - Data pipeline for real-time monitoring
- Geolocation on vendor master
a. Example: Conflict of interest/ghost vendors - Combine with eDiscovery for advanced analytics
a. Text sentiment analysis on subject email or text message
b. Company device activity logs - Other benefits
a. For massive review, deploy RPA
b. Helpful technology such as OCR
有些我們不會稱作 fraud,如 Compliance / Security,但也很適合透過 DS 去解決的例子。
- Contract Completeness | finding missing contracts in contract repositories
- System Vulnerability | Mapping external datasets (security scores of apps) to internal app usage data
- User Access Management | comparing the average access by team to detect unauthorized accesses
可以簡單使用 dashboard,可以找出不太正常的 access 狀況,雖然不是 fraud detection,但也很非常適合用 DS 做的應用。 - Payment Analytics | creating metrics (i.e., date-interaction, ratios, etc.)
- Risk Assessment | Integrating quantitative method in addition to qualitative assessment
- Test User Account Analysis | detect artificial accounts based on account behaviors

- For data scientists:建議不要使用太技術的 term,會阻礙溝通,多用應用場景去解釋,成為中間的橋樑幫助合作。
- For compliance:可以培養一些 DS/ML 知識,進而將 DS/ML 知識應用於日常工作中。
- For management:投入資料科學資源於compliance/finance去更有效率地解決問題。
五、工商時間
Quitting In New York
[衡想辭職在紐約]一對紐約夫婦上班到懷疑人生之後開的節目。我們會從科技業的職場閒聊、美國生活、崩潰育兒、聊到到好友間的離經叛道愛情故事啦!每週二晚上八點更新喔!
Harry ‘ s Podcast:衡想辭職在紐約 Quitting In New York
Harry 每天工作遇到舞弊稽查,都是遭遇人性的黑暗面,經過五年的洗禮之後,難免需要有出口排憂解悶。Harry ‘s Podcast 的主要分享主題是:
- 工作上發生的趣事
- 美國生活的分享
推薦大家 Harry 優質的 Podcast 頻道,了解更多 Harry 的生活趣事。
六、Q&A
Q1:家庭方案有限定住在同一個地方,用什麼方式可以去判斷說謊呢?
- 目前我們還沒有真的去抓,但這些都會有 IP資訊,可以根據此特徵去判斷。
Q2: 請問在 Spotify data analytics manager這個role是不是比較接近 DS & business(compliance in this case)?所謂的business initiative 還是由business提出?
- 沒錯。
- 不一定,如果你是資料科學部分,但你有分析的想法依然可以去溝通看看。
Q3:碩士學位在 Spotify 的 DS 職位很重要嗎? 我現在在考慮要不要去念 BA/DS 的研究所,想請問你有什麼建議嗎?
- 主要是需要有 portfolio、實戰經驗,以我目前看過的經驗,學、碩、博士都有。side project 幫助比較大,有的日常工作是做音樂分析,但平常的side project 是做 NBA 的 dashboard。
- 應該去考慮研究所可以帶給你什麼知識,有助於你取得工作。
Q4:通常 vendor 的家數應該不多吧?請問資料量大概是多少呢?會不會資料過少無法分析?或者有 imbalanced data (真正有偷盜行為的 vendor 不多)
- 會發生 imbalanced data 情況,但是有方法可以解決,像是 clustering 就比較不需要那麼多資料,如果是二元模型就可能比較需要多一點資料。
Q5:請問 Harry 是如何說服公司的其他人去相信 ML 的結果是可以準確抓出詐欺行為的?
- 需要去驗證(validate),透過這樣的循環,去說服外部的律師或者內部的內稽人員,透過這樣的互動去讓雙方都參與並相信這個方法是有幫助的。
Q6:如果現在是資料科學家,對於 Compliance and Fraud Detection 相關Domain 有興趣的話,請問是否可以推薦一些學習這個領域的資源呢?
- 我的背景是 Accounting and Finance 出生,同時也是美國舞弊稽查師(CFE),所以我有許多經驗在此領域;資料科學方面則是與大家一樣,透過Leetcode & Medium & TWDS 以及其他線上課程,與大多數人應該沒有太大的不同。
Q7:除了Clustering 之外,還有哪先用在 Compliance 常用的ML Technique呢?謝謝
- 透過已知的案例去預測二元分類模型。
Q8:Comliance 結合 DS 的領域真的很有趣,但想請問這種工作性質怎麼設定KPI?因為這種工作很關鍵(一不小心就被告)但又比較難有效益(不確定省下多少錢)
- 可以肯定地是 KPI 絕對不是由查出多少案件而定,因為那樣會促使員工挑選簡單的案子去解決,是一個非常難的問題,但絕對不是業績制。
Q9:想請問像是剛剛說到 DS 與其他團隊的溝通是很重要的,那除了透過這種溝通獲得需要分析的事件外,會有 DS team 想到分析什麼,然後提出成果的嗎?
- 對的,我自己的情況就是, DS team 分享一些可能用的方法,我們將其使用在Compliance上。
Q10:請問有聽過 fraud/risk 轉到 business side 當分析師的例子嗎? 怎麼達成的?
- 有,我的經驗中,如果是做 fraud 出身的,會有幾個人格特質,比如說常常講話,會透過interview去了解情況。
- 不太一定,當在做 fraud 的時候,你的領域知識會比較深,那麼補足相關DS 知識就可以進入了。
Q11:想請問剛剛提到的 clustering 之後找出最重要的幾個特徵,然後制定rule-based 的預測方法,請問實務上怎麼在貴但是準確率較高的 model-based or 便宜但可能準確率比較低的rule-based之間取捨?
- case by case,假設公司有200人,你告訴老闆說要找 fraud detection 的model,就比較不是一個當務之急的問題;那如果是公司有15萬人且遍佈在世界各地,且policy、regulation都不一樣的話,那麼ML-based 絕對是比較好的選擇。所以是取決於你公司專案的scale。
Q12:請問對於DS領域的manager的career path,你建議需要培養哪些能力跟須要注意那些契機?
- 這是一個很大的問題,溝通是關鍵,coding 不是主要的工作,主要是做現在的分享以及將部門結合在一起合作。
Q13:What’s the difference between working in Spotify and Johnson & Johnson?
- Johnson & Johnson 可以比作台灣的中華電信,有很大的客戶以及覆蓋率,他的成長不會像科技公司爬升那麼快,Spotify 就是一個中型企業,競爭對手Apple、Amazon,會比較有挑戰大鯨魚的熱血感。
Q14:可以分享如何找到推動 Clustering 的 features 或是找到關鍵的特徵嗎?
- SHAP value,透過此方法去反推,有時候會發現有的driving features會沒有辦法幫助你 fraud investigation,這種情況也會捨棄它。
Q15:目前聽起來每個應用都要 case by case 去談,花了很多力氣去溝通,想請問有沒有可以標準化或是變成平台的做法嗎?
- 這有點算是舞弊稽查的成本鴻溝,像現在我大概每3個月都會發現新的fraud 類型,如果你今天問這個問題是從節省成本角度出發,或者從資料科學家的角度,就是能不能建立一個模型去捕捉多種形態的fraud,這也是一種方法。
Q16:Spotify 的個人化推薦比其他 benchmark 精準,請問可以分享嗎?
- 關鍵點在於強化學習,這是我們最近研究的方向。
Q17:對於即將碩士畢業的 DS,除了side product 外,有什麼其他可以累積經驗或是提升不同領域之間溝通的方法嗎?
- side-project 就是提升經驗的方法之一,所以盡可能去做,使 side-project可以到達分享的程度,就可以累積經驗了。
- 練習溝通有很多方法,像是我今天的演講也是其中之一,可以透過協作、在公司作跨部門的溝通,主動去尋求自我練習的機會。
Q18:請問你從 Compliance domain 轉到資料分析,除了通過自修、Leetcode 外,有做 side-project or portfolio 嗎?
- 有的,而且我其實是在公司內部做的,因為我發現沒辦法在公開的github 做 side-project,因為沒有相關的資料,所以我是在公司內部主動尋求機會。
- 比如說,我手邊的案子查完了,但我想要挖得深一些,這樣的經驗有很大的幫助,甚至有的案子透過這樣的方式,有發現到更多的 insight。所以做 side-project 是很值得花時間的。
筆手:Aaron Yang
校稿:Harry Lu
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!